· Dave Brewster (dave@augustdata.ai) · rag · 6 min read
RAG: What is Retrieval-Augmented Generation in Eidolon?
Part 1: Define RAG and its components.
This is Part 1 of a 3 part series on Retrieval-Augmented Generation.
For information on configuring RAG storage in Eidolon, see Part 2: How is RAG storage configured in Eidolon.
For information on configuring RAG retrieval in Eidolon, see Part 3: How is RAG retrieval configured in Eidolon.
Retrieval-Augmented Generation (RAG) is a powerful technique that combines the strengths of retrieval-based and generation-based models to create more flexible and accurate language models. In this series, we will explore how RAG works, how it is implemented in Eidolon, and how you can use it to build powerful and flexible language models.
What is RAG?
RAG is a technique that combines the strengths of retrieval-based and generation-based models to create more flexible and accurate language models. Retrieval-based models are good at finding relevant information from a large corpus of text, while generation-based models are good at generating new text based on a prompt. By combining these two approaches, RAG can generate text that is both accurate and flexible.
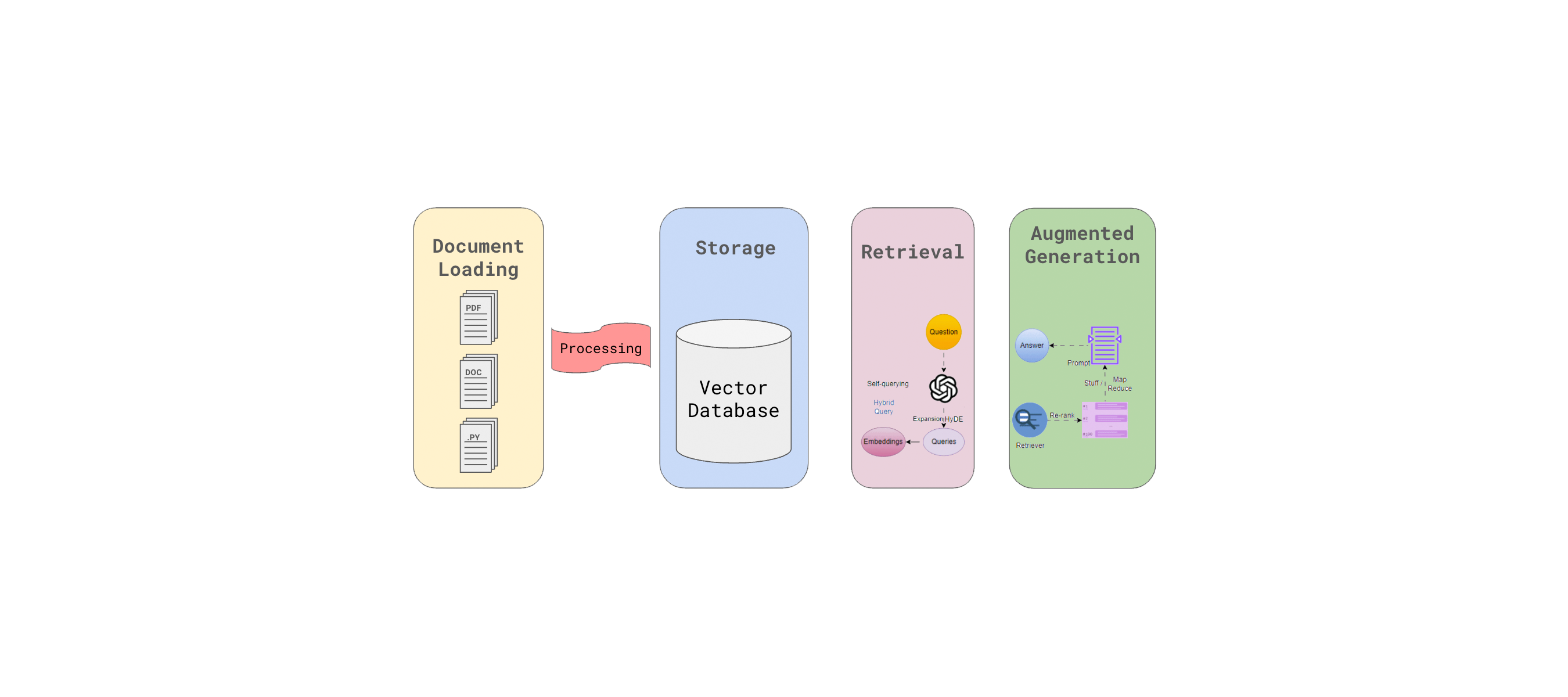
There are two parts to RAG, storage and retrieval. Storage is the process of storing information in a way that allows us to execute textual queries against a data store that find information “close” to the query. Retrieval is the process of finding relevant information from the data store and using it to augment the generation process.
Before we can focus on retrieval we need to discuss where and how data is stored so that it can be retrieved and used in the generation process. The basic concept of RAG is that we are retrieving information from one or more data stores and augmenting the generation process with that information. This information can be anything from simple facts to complex structured data. The key is that the information is stored in a way that allows it to be retrieved and used in the generation process.
Data Storage
Unstructured data is typically stored in a Vector Database. A vector database is a database allows us to find information “close” or “similar to” the user query. Information is stored as vectors, which are mathematical representations of the data. We then use mathematical techniques to find the vectors that are closest to the query. This allows the data to be easily retrieved and used in the generation process. Vector databases are typically used to store text data, such as documents or articles, but can also be used to store other types of data, such as images or audio.
Information that is stored in a vector database is indexed using an embedding model. An embedding model is a mathematical model that maps data to a high-dimensional vector space. All information stored in the vector database, text, images, etc… must first be converted into a vector using the embedding model.
Different document types are first pre-processed to extract items that can be embedded accurately. For example, PDF files are converted to text and any contained images with each embedded separately. Code is split into it’s fundamental components and each component is embedded separately. This is typically called the “parse” phase.
Once a document is parsed, it is usually split into smaller chunks, such as paragraphs or sentences, and each chunk is embedded separately. This allows the embeddings to capture the meaning of the text at a more granular level, making it easier to retrieve relevant information. There are quite a few techniques to do this and tuning this process can yield marginal improvements in the quality of the embeddings.
There are also techniques to combine embeddings from different sources, such as text and images, to create a more comprehensive representation of the data. We can even call into other models to summarize or translate the data before embedding it.
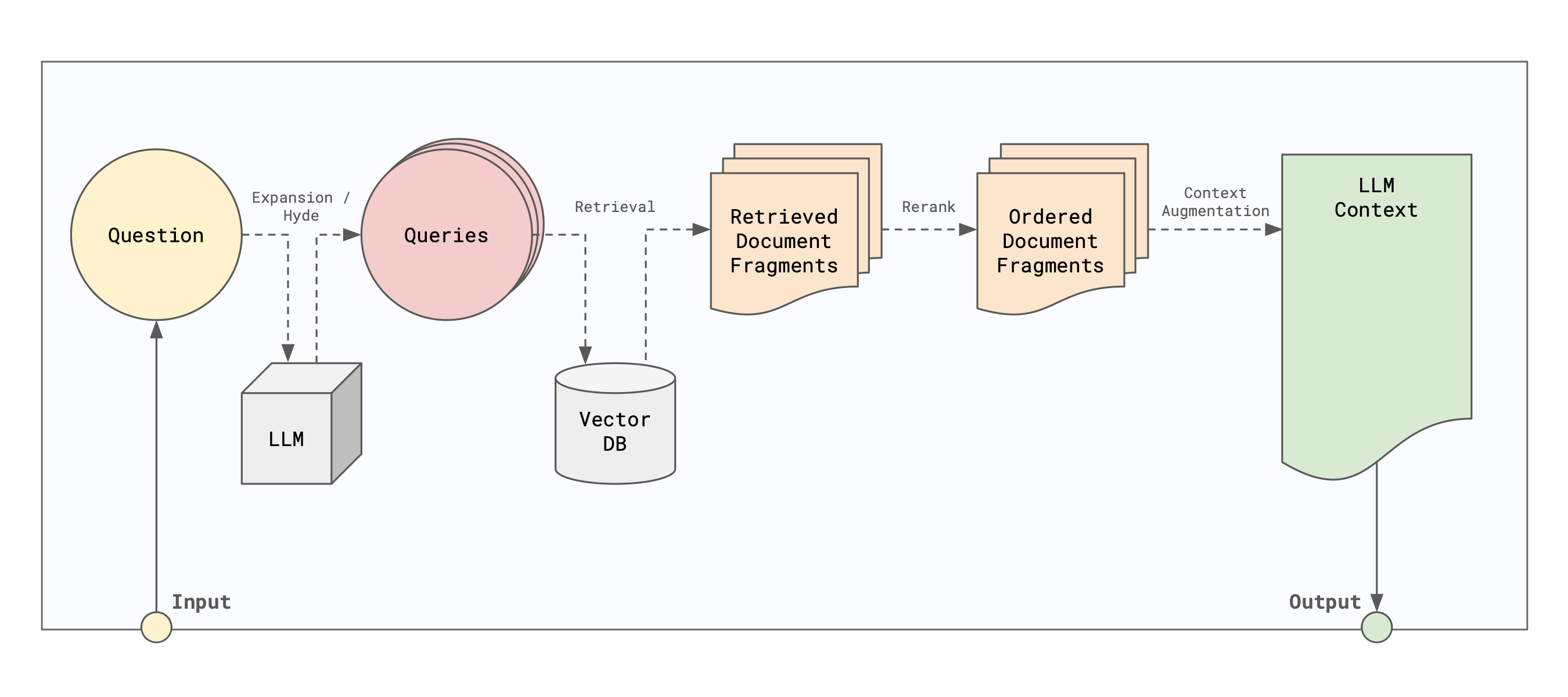
Retrieval
After a user submits a query, the query is embedded using the same embedding model that was used to embed the documents. The embedded query is then used to search the vector database for relevant information. The search process is typically done using a nearest neighbor search algorithm, which finds the documents that are closest to the embedded query in the vector space. The retrieved document fragments are then passed to the generation model, which uses them to generate a response to the user’s query.
This extremely simple example is the basis for the RAG model. However, it rarely yields accurate results. First off, the user’s question rarely maps well to the embeddings of the documents. Some sort of reformulation of the user’s query is needed. Secondly, once we’ve rewritten or created multiple queries, we need to retrieve that information and rationalize it in some way before we send it off the LLM for generation. For example, we might want to summarize the retrieved information, or we might want to combine information from multiple sources and rerank it using a technique like MMR.
Retriever Agent
We have an agent in Eidolon that can process both the storage and retrieval parts of RAG. This agent is called the Retriever Agent.
The Retriever Agent is designed to be a simple, one-stop-shop for small to medium-sized RAG workloads. It automatically handles the loading, parsing, splitting, and embedding of documents, and monitors the configured loader for changes to the data, automatically reloading the data when changes are detected.
By default, the Retriever Agent uses the AutoParser parser, which detects the type of document and uses the appropriate parser to extract the text. It is also configured to use the AutoTransformer transformer, which automatically selects the appropriate transformer for the document type. The parser is responsible for extracting the text from the document, while the transformer is responsible for splitting the text into smaller chunks for embedding.
The Retriever Agent also includes a preconfigured question transformer and document reranker. The question transformer is responsible for reformulating the user’s query to better match the embeddings of the documents, while the document reranker is responsible for combining and reranking the retrieved documents before passing them to the generation model.
By default, the Retriever Agent uses the MultiQuestionTransformer question transformer, which generates multiple reformulations of the RAGFusionReranker document reranker, which combines and reranks the retrieved documents using a technique called RAGFusion to rerank the results based on the relevance of the documents returned from teh reformulated queries.
In the next part of this series, we will focus on the data storage part, how it is implemented in Eidolon, and how you can use it.